t2bot의 자동 색인 시스템을 이용하여 한국어 텍스트(KBS 9시 뉴스)에서 색인어를 추출하여 예제로 사용하였다. 예제처럼 형태소 분석된 색인어를 추출해서 사용하려면 자동 색인 시스템을 이용하여 변환해 두어야 한다. 다음은 색인어 추출에 대한 매뉴얼이다.
자동 색인 시스템: m64-80tpx.exe
・동작 환경: PC 윈도우
・한글 코드: 통합 완성형(CP949, 멀티바이트)
・다운로드: tpx-20210930.zip (2021년 9월 30일 버전으로 날짜는 바뀔 수 있음.)
압축 파일을 풀면 1개의 사전 폴더와 10여 개의 파일이 있는데 이 중에서 실행 파일은 ‘m64-80tpx.exe’이다. 이 파일은 PC 윈도우 환경에서 실행되는 것으로 통합 완성형 코드를 지원하기 때문에 유니코드로 작성된 텍스트 파일은 통합 완성형 코드로 변환해야 한다.
C:\Users\ia\Desktop\send>m64-80tpx.exe 폴더명
텍스트 파일을 매개변수로 전달하여 자동 색인을 수행한다.
C:\Users\ia\Desktop\send64>m64-80tpx.exe test11.txt
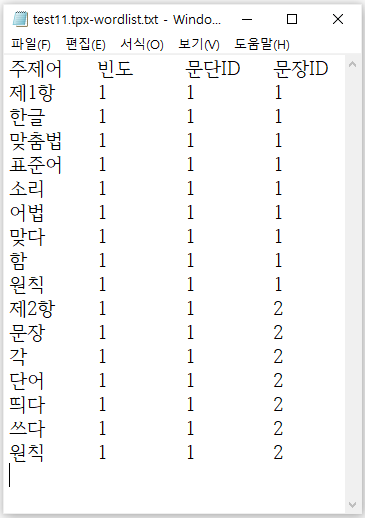
실행이 끝나면 [그림 부록-8]과 같이 탭(tab) 문자로 구분된 “주제어(색인어), 빈도, 문단ID, 문장ID” 형식으로 ‘~.tpx-wordlist.txt’ 파일에 저장한다. 실행 결과를 보면 2개의 문장으로 이루어진 1개의 문단에서 단어를 추출한다. t2bot 자동 색인 시스템은 확률 기반 모델로 불완전한 단어가 추출될 수 있으며, 명사를 비롯하여 동사, 형용사, 부사 및 감탄사 등 거의 모든 실질 형태소를 색인어로 추출한다. 그러나 문법 형태소에 해당하는 조사와 어미는 추출하지 않으며, 실질 형태소 중 ‘하다, 되다’와 같이 어휘적 의미가 약한 단어도 추출하지 않는다.

폴더를 대상으로 색인어를 추출하려면 파일명 대신에 폴더명을 지정한다.
C:\Users\ia\Desktop\send>m64-80tpx.exe 폴더명
한편 ‘m64-80tpx.exe’ 파일은 자동 색인 서버와 자동 요약 서버 기능이 통합되어 있으며 이에 대한 매뉴얼은 t2bot 사이트에서 확인할 수 있다.
사전 경로 변경: m64-80tpx-sysdic.ini, m64-80tpx-userdic.ini
다운로드한 t2bot 자동 색인 시스템의 실행 경로가 예제와 다를 경우에는 실행되지 않으므로 2개의 환경 설정 파일에서 3개의 ‘PATH=~’를 찾아 사전 경로를 변경해야 한다.
#. m64-80tpx-sysdic.ini 파일에서 경로 지정(PATH=~ 2곳)
PATH=C:\Users\ia\Desktop\send\dic\
#. m64-80tpx-userdic.ini 파일에서 경로 지정(PATH=~ 1곳)
PATH=C:\Users\ia\Desktop\send\dic\
자동 색인 결과 파일 읽기
자동 색인 시스템은 텍스트를 문단 단위로 분할한 후에 다시 문단에서 문장으로 분리한다. 문장에서 색인어를 추출한 후에 색인어가 소속된 문단과 문장의 ID를 기록한다. 이 때 모든 색인어(주제어)는 빈도가 ‘1’이며, 한 문장 안에 같은 색인어가 2개 이상 있더라도 빈도를 통합하지 않고 순서대로 모두 기록한다.
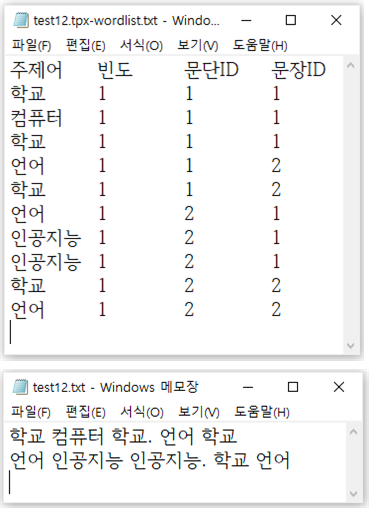
자동 색인 결과: ~.tpx-wordlist.txt
자동 색인에 의해서 생성된 파일에서 색인어를 단어 목록(list)과 단어 빈도 사전으로 변환하는 방법은 다음과 같다. ‘~.tpx-wordlist.txt’ 파일은 탭 문자로 구분된 “주제어(색인어), 빈도, 문단ID, 문장ID” 형식으로 되어 있어 split() 함수로 호출하여 항목을 분리한 후에 첫 번째 항목인 ‘주제어’만 문자열(HGTpxText)로 모은다. 예제에서는 split() 함수를 이용하여 HGTpxText 변수를 단어 목록(HGTpxList)으로 변환한 후에 루프를 통하여 단어 빈도(WordFreq) 사전을 생성한다.
[예제 append-20]
def GetHGTpxText_TpxFile(filename, encoding='utf-8',
IgnoreError=False, ReadNum=-1, PrintTextFlag = False):
from pathlib import Path
# 결과를 텍스트로 반환
HGTopicText = ""
if(type(filename) == str):
filename = Path(filename)
if filename.is_file():
if filename.exists():pass
else: return HGTopicText
else:
print("file not found: %s" %filename)
return HGTopicText
errors = None
if(IgnoreError == True):
errors = 'ignore'
file = open(filename, 'r', encoding=encoding, errors=errors)
TopicHeader = None
ReadCnt = 0;
RealReadCnt = 0
while True:
try:
line = file.readline()
if not line:
break
if(PrintTextFlag == True):
print(line)
line = line.strip() # 양끝 공백문자 지움
if(len(line) > 0):
#-if(line != None): HGTopicList.append(line)
word_tok = line.split('\t')
if(word_tok != None):
# format: ['주제어', '빈도', '문단ID', '문장ID']
if(ReadCnt == 0): # 맨 처음 읽음
TopicHeader = word_tok
else:
HGTopicText += word_tok[0] # '주제어'
HGTopicText += '\t'
#
RealReadCnt += 1
else: # 내용은 없고 줄바꿈만 있는 경우
if(len(HGTopicText) > 0): # 앞에 실제 텍스트(주제어)가 하나라도 있을 때만 줄바꿈을 넣어준다.
HGTopicText += '\n' #
except UnicodeDecodeError as UDError:
print('[',filename,']', '\n', (ReadCnt + 1), 'line ', UDError)
pass
###
ReadCnt += 1
if(ReadNum > 0): # 읽을 개수 검사
if(ReadCnt >= ReadNum):
break
###
file.close()
###
return HGTopicText
#-----
#-----
filename = Path(filepath + 'test12.tpx-wordlist.txt')
encoding='euckr'
HGTpxText = GetHGTpxText_TpxFile(filename, encoding=encoding)
print('HGTpxText:', HGTpxText)
#-----
HGTpxText.rstrip() # 문서 끝 쪽에 있는 공백문자 지운다.
HGTpxList = HGTpxText.split()
print('HGTpxList', HGTpxList)
#-----
WordFreq = {}
for word in HGTpxList:
if(word in WordFreq):
WordFreq[word] += 1
else:
WordFreq[word] = 1
print('WordFreq:', WordFreq)
>>>
HGTpxText: 학교 컴퓨터 학교 언어 학교 언어 인공지능 인공지능 학교 언어
HGTpxList ['학교', '컴퓨터', '학교', '언어', '학교', '언어', '인공지능', '인공지능', '학교', '언어']
WordFreq: {'학교': 4, '컴퓨터': 1, '언어': 3, '인공지능': 2}사용자 불용어 사전: ./dic/임시-poststop-adder1.txt
t2bot 자동 색인 시스템이 추출한 색인어 중에서 적합하지 않거나 불필요한 단어는 [그림 부록-10]과 같이 ‘./dic/’폴더의 ‘임시-poststop-adder1.txt’ 파일에 단어를 등록하면 불용어로 처리된다. 불용어 사전을 갱신하여도 실행 프로그램을 새로 시작하기 전까지는 반영되지 않으므로 반드시 재실행한다.
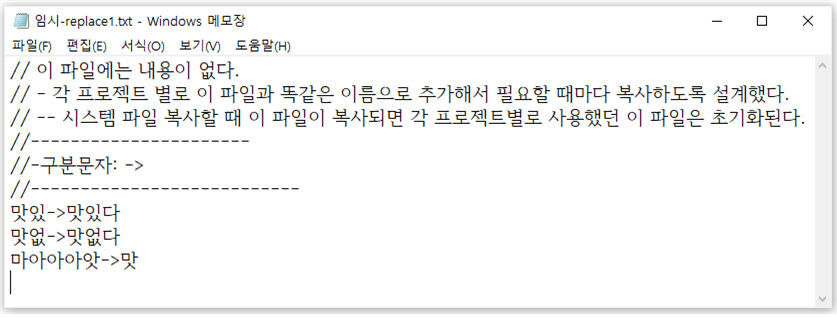
색인어 변경 사전: ./dic/임시-replace1.txt
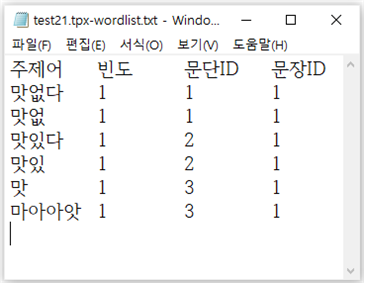
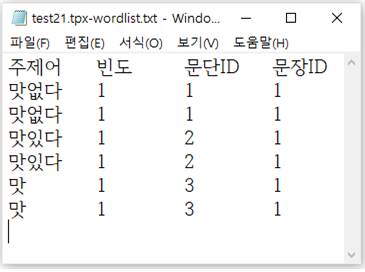
자동 색인 시스템에서 추출된 색인어를 다른 색인어로 변경하려면 [그림 부록-11]과 같이 ‘./dic/’폴더의 ‘임시-replace1.txt’ 파일에 단어를 등록한다. 예를 들어 test21.txt의 철자 오류 단어는 자동 색인을 수행하면 ‘맛없, 맛있, 마아아앗’ 등의 부적절한 색인어가 추출된다. 철자 오류를 고려하여 맞춤법에 맞는 색인어로 변경하기 위해서 [그림 부록-11]과 같이 등록해 두면, 자동 색인이 끝나고 [그림 부록-12]와 같이 변경된 색인어로 추출된다. 색인어 변경 사전에 등록할 때는 ‘->’ 문자열로 구분하며 실행 프로그램을 새로 시작하기 전까지는 변경 내용이 반영되지 않으므로 반드시 재실행한다.